简介
RDMA全称Remote Direct Memory Access。 要了解RDMA,得先了解DMA。DMA技术主要是为了加速IO访问,适用于当CPU成为瓶颈的场景。在传统架构中,CPU要从磁盘读取数据时,CPU会发指令给设备驱动,驱动处理完成后,通过中断方式通知CPU进行读取。当中断数量增长时,CPU会成长瓶颈。一个解决思路就是DMA,即将CPU这部分能力独立放在一个控制器中,即DMAC(DMA Controller),CPU只在一个DMA流程开始和结束时才与IO有交互,其余时间都交予DMAC处理。这样就去除了CPU瓶颈,让CPU时间更加集中在计算方面。
RDMA思路类似,它要解决的是网络传输过程中服务器端数据处理的延时。大致思路是将数据从一台计算机的内存传输到另一计算机的内存中,中间无需双方操作系统的介入。这适合于高吞吐、低延迟的网络。下面我们来详细看看。
RDMA特性
| RDMA特性 | CPU消耗少 | 延迟低 | 内存带宽大 |
|---|---|---|---|
| 主机不处理网络传输(如TCP/IP) | ✓ | ✓ | ✓ |
| 使用带标记缓冲区,无需接收内存拷贝 | ✓ | ✓ | |
| 越过操作系统,直接把硬件映射到用户空间,减少了上下文转换 | ✓ | ✓ | |
| 异步API(socket API是同步的) | ✓ | ✓ | |
| 保留消息边界,因而可以分享应用头部和数据 | ✓ | ✓ | |
| 消息层次(而不是packet)层次上中断合并 | ✓ |
RDMA方案
现在已知的方案有三种,InfiniBand, RoCEv1/2, 以及 iWARP。如下图
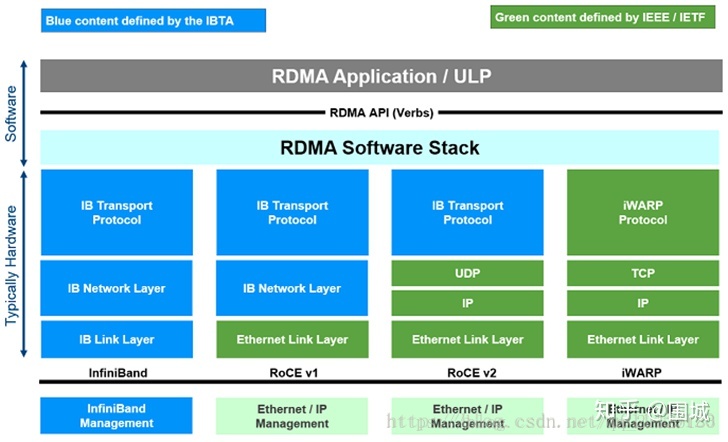
在具体介绍前先引入两个组织,一个是IBTA,另一个是IETF。IETF各位可能很熟悉了,定义了互联网行业的很多标准。IBTA,全称InfiniBand Trade Association,即InfiniBand行业协会,是专职于制定和推广InfiniBand协议的组织。
从图上可以大致看出,InifiBand是纯粹独立的解决方案,没有使用任何TCP/IP技术;而iWARP则相反,完全基于TCP/IP协议栈提供;介于两者之间的方案则是RoCE v1/2。
iWARP与RoCEv1/2,这两种协议并不兼容,也就是支持RoCE协议的网卡不能与支持iWARP协议的网卡交换数据。
InfiniBand
InifiBand,是由IBTA组织推广的支持RDMA的新一代网络协议。它是一种高性能网络协议栈,标准形态对标的是整个TCP/IP协议栈。因此,如果要使用,需要配备支持该技术的NIC和交换机。
iWARP
iWARP, 全称internet Wide-area RDMA Protocol,是由IETF主推的一种规范和方案,简单说就是RDMA over TCP。
这允许在现存的标准互联网上使用RDMA技术。与其它技术类似,如果需要提升性能,需要网卡支持iWARP协议,以便进一步offload CPU。如果不使能网卡的offload功能,通常来说RDMA的性能优势就没有了。
iWARP主要由Intel和Chelsio这两家公司在推进。
RoCE v1/v2
RoCE,全称RDMA over Converged Ethernet,总体来说是一种网络协议,允许通过以太网实现RDMA访问,发展至今包括2个版本协议。这个方案主要是Mellanox这家公司在跟进。
RoCE v1
如上图所示,v1版本是一种链路层协议,2层以下是标准Ethernet协议。因而,它可以在同一个广播域内实现RDMA访问。
RoCE v2
v1版本已经有一定通用性了,但还不够。所以v2版本出现。 同样如上图所示,v2版本复用了TCP/IP协议栈的UDP以下几层,只在应用层封装了IBTP。 可以理解,v2方案的适用场景超过v1,但是性能相对v1版本会有下降。
Ceph RDMA 方案
RDMA的优势是低延迟、低CPU开销。Ceph如果想要使用RDMA技术,有两个思路。一是作为通信组件,提升通信效率。二是作为NVMe-oF接入。
作为通信组件 (iWARP)
Ceph社区已经有针对性的作了一些改造,如下图。
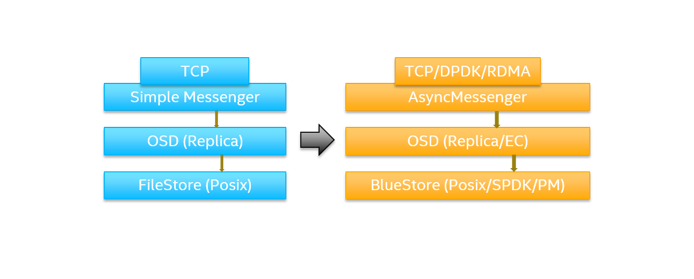
在Ceph中,所有通信都被封装到通信组件 messenger 中。当前,ceph 实现了三种 messenger,包括 simple, async 和 XIO。messenger 负责所有上层组件的通信,如 OSD, MON, MDS等。
现在有一些项目致力于把RDMA整合到Ceph中去,XIO messenger 是其中之一。XIO 基于 Accelio 搭建 (一种基于RPC的高性能异步通信加速库) 实现,于 2015 年合并到 Ceph 主分支代码中。它支持了多种 RDMA 协议,包括 InfiniBand, RoCE 和 iWARP。不过通过社区反馈,这个方案有扩展性和稳定性的问题,所以现在基本不再维护了。
另一个项目关注async messenger。相比于simple messenger,async 更加高效,并且占用较少 CPU 资源。该项目集成了 InfiniBand RDMA 协议。架构如下图
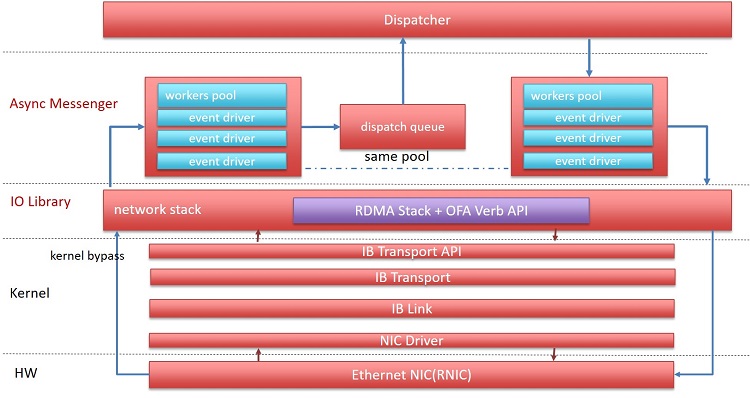
Intel 将 iWARP 集成到了 async messenger 中,并作了一些性能测试。见参考材料2。
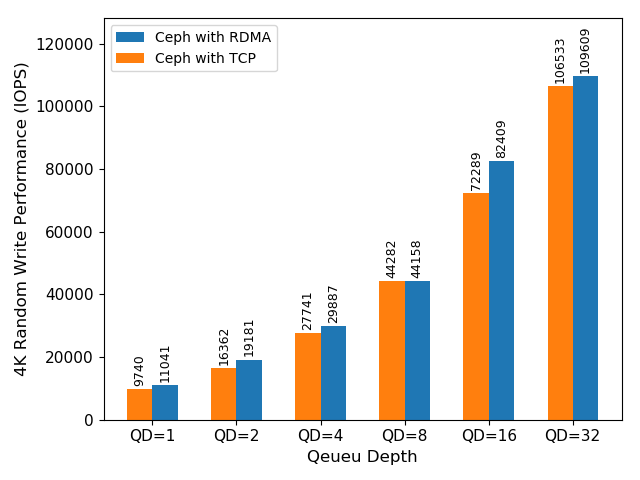
从测试数据中看出,使用 iWARP 和 TCP/IP 的 ceph async messenger, 前者比后者在4K随机写上性能提升至少 17%。
这一方案后续工作有两方面:
-
性能优化: 去除从RDMA message 到 async messenger 的消息copy。
-
使用 NVMe-oF: 这是为了把存储节点和CPU解耦,以提高整个方案的TCO。原因是,对于4K随机读写的work load,CPU是瓶颈。
作为NVMe-oF
这个方案架构如下图
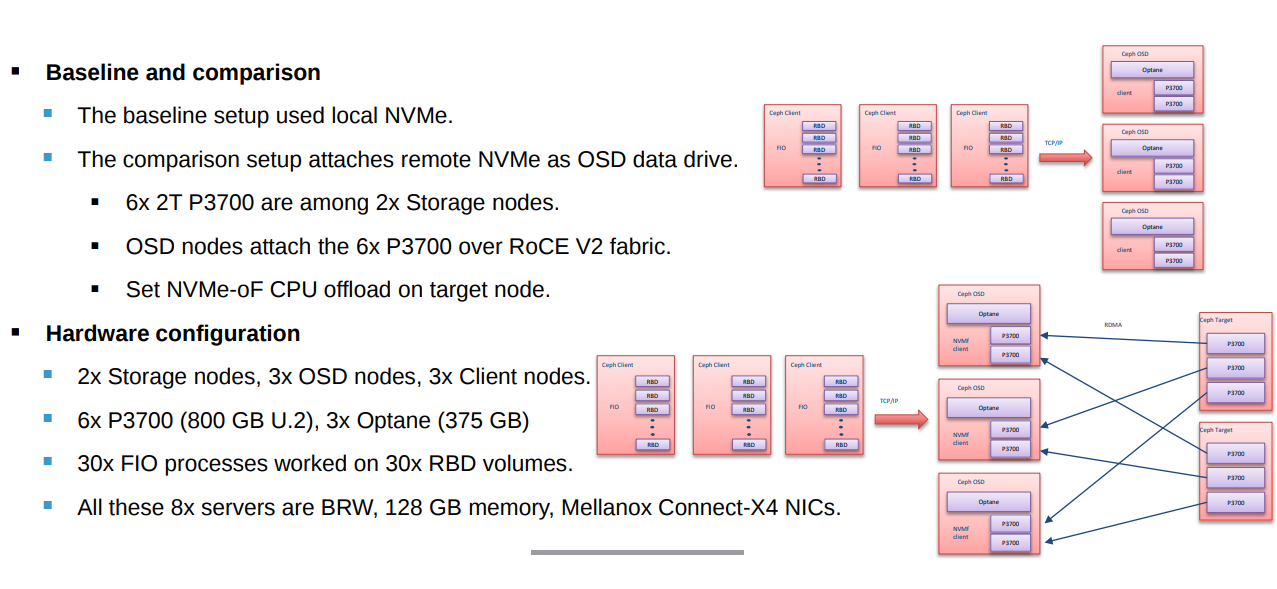
主要思路是将NVMe SSD和OSD节点分开,解决 local NVMe 方案下,CPU 成本瓶颈后的扩容耦合问题,并保证新的架构本身不会降低性能和成为新的瓶颈。
如参考材料3所示,经POC验证,该方案有以下特点:
- 基本不会降低性能
- 本身CPU开销很低;
- 当QD < 16 时,latency 基本不变
- 解耦OSD扩容
- 当OSD CPU上升时,直接扩容OSD节点,后端存储点可以不用扩容。在达到NVMe性能瓶颈前,基本不用扩容。
- 可以复用已有的全Flash投资。