Intro
本文记录 longhorn-engine 项目的源码分析,包括模块分析及主要流程代码级分析
代码组织及模块介绍
longhorn-engine 负责单个controller或replica的逻辑,承担整个longhorn项目的主要数据流。
从代码组织结构看,大致划分如下:
- main.go: 入口函数,主要定义cli。
- app: 子命令入口模块, 包括多个子命令。分别是
controller,replica,frontend,syncAgent等。 - pkg: 存放各类子命令的相关处理逻辑,基本对应
app中的各类子命令 - proto: 存放protobuf的协议生成代码
- package: 容器镜像制作相关,包括Dockerfile等
- integration: 集成测试工具
- scripts: build工具
启动分析
我们通过main.go来分析下启动过程。
engine项目的启动模块有点特殊。它有两种模式,一种是正常的longhorn-engine cli,另一种是通过reexec实现的ssync的cli。
ssync是用于读写单个后端sparse file的工具。ssync需要通过软/硬链接的方式,修改其启动命令为ssync才能触发。这里不展开ssync的逻辑,我们专注看longhorn-engine cli部分。
lognhorn-engine cli通过longhornCli()初始化和启动。它包括了10+的子命令,如下:
a.Commands = []cli.Command{
cmd.ControllerCmd(),
cmd.ReplicaCmd(),
cmd.SyncAgentCmd(),
cmd.SyncAgentServerResetCmd(),
cmd.StartWithReplicasCmd(),
cmd.AddReplicaCmd(),
cmd.LsReplicaCmd(),
cmd.RmReplicaCmd(),
cmd.RebuildStatusCmd(),
cmd.SnapshotCmd(),
cmd.BackupCmd(),
cmd.ExpandCmd(),
cmd.Journal(),
cmd.InfoCmd(),
cmd.FrontendCmd(),
VersionCmd(),
}
其中ControllerCmd, ReplicaCmd, SyncAgentCmd是启动daemon进程,我们重点看这几个。
ControllerCmd
该子命令负责启动一个controller,同时可以指定后端的n个replica的连接地址。一个controller负责读写一个volume。
启动函数是startController(),其主要逻辑如下:
- 根据命令行参数初始化配置,包括
frontend类型(支持tgt-iscsi,tgt-blockdev,rest,socket这四种),backend类型(支持tcp,file这两种,默认为tcp)。 - 调用
NewController()创建controller数据结构,顺带启动一个线程,用于收集metrics。 -
调用
controller.Start(), 根据命令行参数replica,创建对应数量的replica backend。a. 根据每个replica地址,创建对应的backend。
1) 根据输入的replica地址,生成2个具体连接地址,其中一个是原replica地址,另一个是在原地址端口基础上加1生成的地址。前者负责control path,后者负责data path。 2) 对control path,我们创建一个临时的replica对应的grpc client,并调用grpc调用 `ReplicaGet` 获取replica信息。 3) 对data path,我们创建`dataconn.Client` 用于处理底层读写请求。并发起grpc call `ReplicaOpen`,告诉对端打开。这类似于OpenFile,表示独占读写。 4) 创建一个监听器,每2s向 replica的data path发起一次ping请求,如果超时则链接报错,并刷掉数据。b. 对每个replica,调用
addReplicaNoLock(), 将backend加入到controller.replicas中,初始化其读写模块,最终启动一个go routine,接收上述data path的监听失败消息。如有,则将replica状态置为ERR。c. 通过grpc调用获取各replica的revision版本信息,检测是否一致。如不一致,则取版本号最大的,其余的replica标记为ERR。
d. 当replica启动成功后,调用
startFrontend(),启动frontend。启动过程涉及iscsi initiator和target的操作,大致包括启动target, 配置LUN和可访问的initiator,再启动initiator,并配置用户可读写的块设备。后面模块分析再展开。 - 启动controller的grpcServer子模块,监听来自命令行参数
--listen <port>设定的端口,并处理volume/replica/snapshot/backup等grpc请求。
ReplicaCmd
该子命令负责启动一个replica,可以响应来自controller的grpc请求以及volume的基于tcp的读写数据流,它向下对接单个sparse file,以实现真正的存储落盘逻辑。
replica 执行环境所在的容器longhorn-instance-manager把宿主Node的根目录映射到容器内的/host下,因此在容器内部可以直接读写宿主Node。
下面我们来看下启动过程。
主要启动函数是startReplica(), 其逻辑如下:
-
根据传入的参数,创建并初始化
replicaServer。a. 创建replica数据结构
b. 根据传入的
volume对应的本地存储目录,初始化qcow本地文件环境,包括revision.count,volume-head-000,volume-head-000.meta和volume.meta这4个文件。c. 检测是否支持fiemap/fibmap功能,即读取sparse file的extends功能。
d. 更新
volume.meta信息,标记为dirty和not rebuilding - 根据待监听的地址,生成3个地址,分别是原地址:端口,原地址:端口+1,原地址:端口+2。这三个分别用于control, data和sync-agent。
- 对于control地址,监听该地址,并基于它创建并初始化grpcServer。
- 对于data地址,监听该地址,并基于它创建rpcServer,接收来自
controller的读写请求并转发给底层volumeFile。 - 默认开启sync-agent,使用sync-agent地址,启动子进程,并启动
sync-agent子命令。
SyncAgentCmd
该子命令负责启动一个sync-agent,用于数据同步。通常会伴随replica,作为它的子进程启动。
它的启动函数是startSyncAgent(),主要逻辑如下:
- 初始化grpcServer,
SyncAgentServer。该server负责接收和处理file, snapshot, backup等操作。 - 监听
ReplicaCmd模块传入的sync-agent端口,启动grpcServer。
除了以上三个子命令之外,其余的命令都是操作命令,且大部分都只能在运行了controller的容器中运行,因为需要与controller模块通信。
模块分析
从上述可以看出,核心模块代码都放在pkg子目录下,具体如下
- backend: controller对应的后端replica,分为
file和remote2种,还有一个实现动态这两种的dynamic模式,默认是dynamic。 - backup: 备份模块,主要用于
sync-agent调用处理备份逻辑,另外还有一个基于qcow的备份逻辑没有看明白,似乎不用了。 - controller: controller模块,
engine启动的主要逻辑都实现在这里。包括controller->replica通信等。 - dataconn: data通信模块,负责
controller和replica之间的data通信,可能是后续的主要优化点。client端负责从unix socket读取数据并走tcp发送到server端,server端负责收取数据并写入到后端存储。 - frontend:
controller的前端入口模块。该模块对应的是iscsi的target模块。分为rest,socket和tgt三种。默认是tgt。 - meta: 程序版本相关数据结构
- qcow: 封装后端存储逻辑,注意只有读走这个组件,写不走。
- replica: replica模块,
replica启动的主要逻辑都在这里。大概包括rpcServer,dataServer,client这3个部分。其中前2个对应了与controller的control path与data path。第3个是replica的grpc客户端,主要由controller和sync-agent调用。 - sync: 该模块主要负责接收并处理
sync-agent的业务逻辑,包括backup/restore,snapshot,replica等手工命令的处理逻辑。部分功能需要在controller侧触发,通过replica/client模块调用replica进程来执行。另外还有sync-agent的grpcServer。 - types: 一些常用的数据类型。
- util: 一些辅助函数。
其核心架构如下图
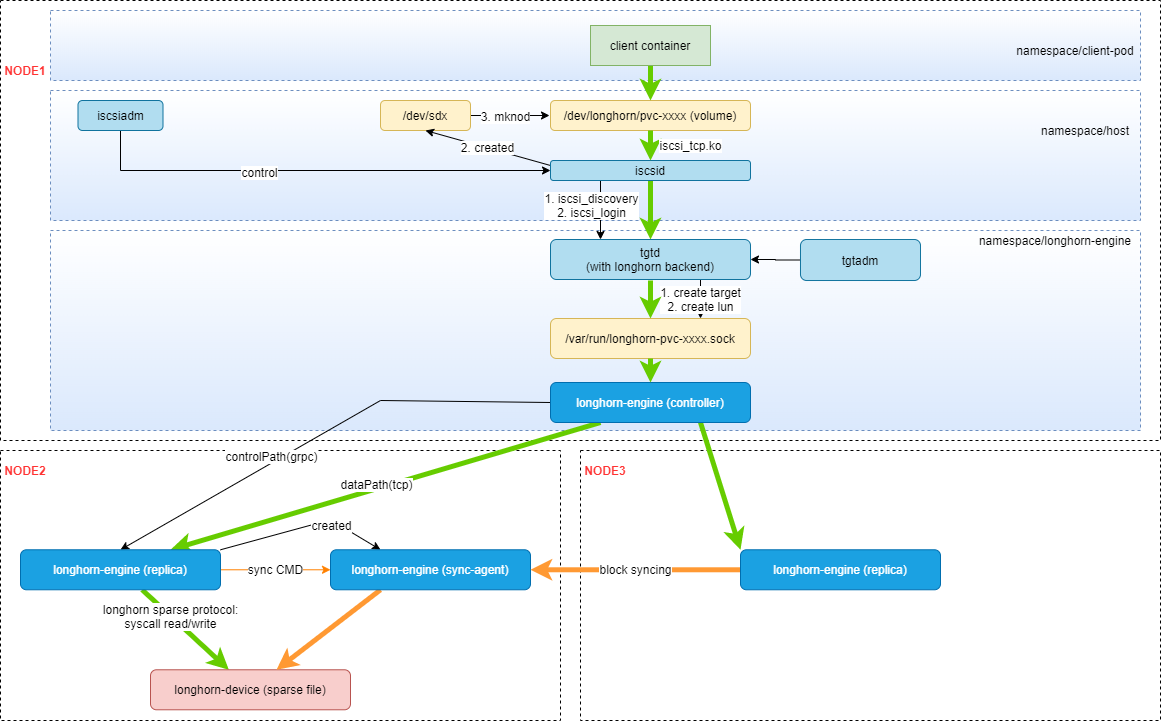
我们重点分析下controller模块,replica模块和sync模块
controller
controller模块的启动过程在前面已经分析过,已经把主要逻辑都疏理过。这里我们重点分析下数据流的读写过程。
读写过程
对controller来说,读写的数据流入口在dataconn模块里。该模拟包含client, server两个组件。
在controller模块中, server组件由frontend/socket初始化,它负责监听iscsi target所对应的unix socket文件,并把该文件的请求向controller后端的多个remote replica client转发。
而remote replica在初始化时,正是使用dataconn中的client作为其数据组件实际转发数据。而在replica进程中,我们启动了dataconn的server,以接收来自controller进程的client请求。
因此整个读写数据流如下:
iscsid <–> tgtd <–(longhorn prot)–> unix_socket <–(longhorn prot)–> dataconn.Server <–> controller <–> replicator.backend <–> dataconn.Cient <–(tcp)–> replica process
data.Server启动时会启动2个goroutine,分别负责读和写。
读goroutine会不断从unix_socket中读取tgtd发来的命令,解析,根据读或写,调用controller的ReadAt或WriteAt进行读写处理。
controller对读写处理是有区别的,因为要处理replica逻辑。下面分别看下。
controller 读
controller调用replicator.ReadAt。这个组件中包括了所有后端replica的客户端连接。
读的策略是round-robin,每次取一个replica读取数据块。如果replica失败,则继续尝试下一个replica,直接全部失败。
controller 写
controller调用MultiWrite.WriteAt。这个组件中包括了所有后端replica的客户端连接。
写的策略是并发对每个后端进行写操作,只要有一个失败,则认为本次写入失败。
replica
replica模块主要负责处理和单个volume的数据交互,并接收和处理来自controller的数据流和控制命令。数据流部主要就是读和写,控制命令包括snapshot, expand等都有。我们分别分析下。
读写
replica的读写主要通过diffDisk结构实现。diffDisk是按LSM的思想组织的,其架构如下图。
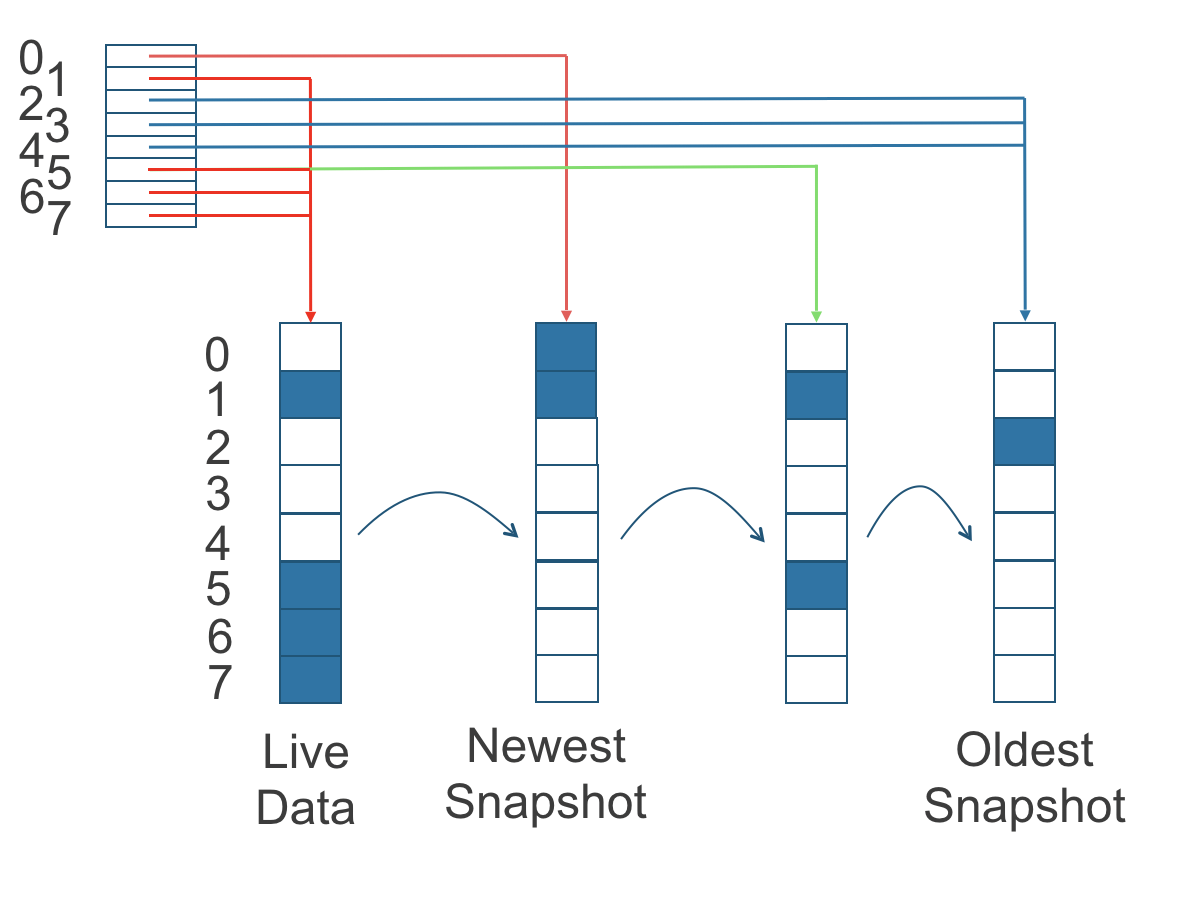
对于写来说,只写liveData层,另外按照Read-Merge-Write的思想来实现。这是针对SSD优化的读写方案。
对于读来说,首先根据读写block索引查找索引表,找到则直接到对应的层去读取数据。找不到则按照从新到旧的顺序,依次查找数据并记录索引,再读取数据。
snapshot
只要1步,创建一个新的volume-head文件,并将其作为最新版本接受读写操作即可。
expand
扩容操作比较简单,只要2步,1是创建一个新的volume-head文件,并truncate其大小为扩容后的大小,2是扩容diffDisk的索引表,使其能容纳扩容后的索引表。
TODO: 不清楚为什么不能支持在线扩容,还需要继续看代码。
sync
该模块负责处理sync-agent的主要逻辑。主要包括从其它replica同步数据,创建backup和从backup恢复数据。
backup
该模块负责处理单个replica的backup/restore。该模块运行在sync-agent进程中,由它接收来自外部的请求,触发针对单个replica的备份和恢复动作。